Well the first and most simple thing you can do is to compute a good old correlation matrix to find which variables have a higher linear correlation with the one you want to predict. 32 A concrete example.

How To Choose Between Linear And Nonlinear Regression Statistics By Jim
Finding the best predictor Python Exercise Pattern Prediction.
. P M θ In this section we dive deeper into what a parameter is what a prior distribution P M θ P M θ is and how we can use a model. I know that R can do what you ask. Usually this is a very straightforward decision.
Stack Overflow for Teams Where developers. History Version 9 of 9. The kernel enables us to make smooth predictions of the parameter vector over the entire domain Wusing the standard kernel ridge predictor.
1 input and 0 output. We defined a Bayesian model as a pair consisting of a parameterized likelihood function and a prior distribution over parameter values. You can download the CSV data file.
Then whichever ones result in the most change in your outcome are likely the most important. Remember we got them from a cluster which was automatically selected with unsupervised machine learning because the cluster showed a. Categorical predictors like treatment group marital status or highest educational degree should be specified as categorical.
Whether we have exact information about X or not will affect the variance for the predicted value. Ive calculated the BMI using the height and weight measurements. Which one is best machine learning approach keras sequential model or random forest regression model for predict from existing parameters of data to generate new synthetic parameters for data.
DXA measurements of body fat percentage are considered to be among the best. P M D θ Prior. I dont know of other free software that can do it.
A will choose the best parameter combinations ordered by the qualifiers like sum profit or profit percent. R² value can be negative for a model that performs arbitrarily worse. P M D θ Prior.
Provided the model is an appropriate fit for your data Id start by making sure your predictors are statistically significant. For the two examples youve given MLE MOM knowledge about the modelprobability function that parameters are estimated from could make a difference. Maximum likelihood has a.
Create pipeline rfecv RFECVestimator LogisticRegression cv 10 scoring accuracy model DecisionTreeClassifier pipeline Pipelinestepsfeatures rfecv model model fit the model on all available data pipelinefitX y make a prediction for one example data load or define any new data unseen data that you want to make predictions upon yhat. Finding the best predictor. Y cd cT Xd Y c d c T X d.
Best_params get_best_parametersparamspnls115 print best_params plot_best_paramsbest_paramstickersstartendBACKEND pltshow The performance of these strategies does not look too bad. In this case we have U kT K I 1 and V w. This Notebook has been released under the Apache 20 open source license.
Keep in mind the. He wants to know if the level of education can predict income. We will also find the variance of the error made by this best predictor.
The most common threshold is p 005 which means that the data is likely to occur less than 5 of the time under the null hypothesis. The more a variable can increase the delta adjusted r-squared the more it is improving your model. I will have duplicated combinations so throw out duplicated combinations 4.
I wanted to know which of social support and diabetes distress was the best predictor of self-care. Advertising Reach developers. From the data you provided in seems that not only the Porosity is linearly correlated with the rock type but also the SandContent.
Significance is usually denoted by a p -value or probability value. A constant model that always predicts the expected value of y regardless of the input features would get a R² value of 0 while a perfect fit model has R² of 10. Likewise continuous predictors like age systolic blood pressure or.
The following parameters have been set to 0 since the variables are a linear combination of other variables as shown. Where k is a matrix whose elements are given by k ij kij for i2 and j2W and is a ridge regularization coefficient. We will start the discussion assuming that the X value is known and later relax this assumption to explore the difference.
A way is to look at the changes in adjusted r-squared delta adjusted r-squared values when each new variable is entered into the model. Your adjusted r-squared values are 0275 for the constant 0366 0480 and 0500. SSE T 2 k 2 where T T is the number of observations used for estimation and k k is the number of predictors in the model.
Stack Overflow Public questions. Both variables are being used to predict a single outcome. Predictor variables in statistical models can be treated as either continuous or categorical.
Known values of X or values of X with uncertainty. A closely-related method is Akaikes Information Criterion which we define as AIC T log SSE T 2k 2 AIC T log. We have basically two important cases to consider.
Talent Build your employer brand. The variables we measured include height weight and body fat measured by a Hologic DXA whole-body system. Generally variable with highest correlation is a good predictor.
Find less important parameters and throw out them 3. Parameters priors and prior predictions. W kT K I 1w.
Statistical significance is arbitrary it depends on the threshold or alpha value chosen by the researcher. You can also compare coefficients to select the best predictor Make sure you have normalized the data before you perform regression and you take absolute value of coefficients You can also look change in R-squared value. P M θ Likelihood.
Mias colleague Jim is working on an independent project. The mean squared error of prediction is M SE Y cd EY Y cd2 M S E Y c d E Y Y c d 2 In this section we will identify the linear predictor that minimizes the mean squared error. Answer 1 of 7.

Making Predictions With Regression Analysis Statistics By Jim

Making Predictions With Regression Analysis Statistics By Jim

Identifying The Most Important Independent Variables In Regression Models Statistics By Jim
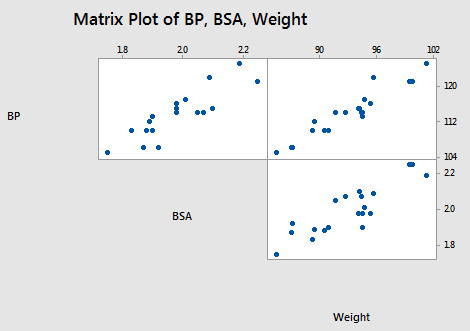
12 3 Highly Correlated Predictors Stat 501


0 Comments